Evaluating Khoj for Helpfulness

Khoj is an open, personal AI that can gather information from your documents and the web to generate accurate answers, paint images, visualize data, and create documents for you.
In this post, we share why and how we implemented an automated evaluation harness for Khoj and Khoj’s performance on modern helpfulness benchmarks using this evaluation harness.
Why We Need Rigorous Evaluation
As we build more advanced capabilities like Research Mode into Khoj, we need a principled approach to track improvements in helpfulness. While we’ve had basic capability tests in Khoj for a while, they weren’t comprehensive enough to measure general helpfulness1.
Users often mentioned that Khoj felt more accurate than other closed AI alternatives, but without quantitative metrics, we couldn’t verify these claims2.
Additionally, as agent capabilities increase, we need more widespread testing to track quality, capability and safety3.
Our Evaluation Approach
Choosing the Right Benchmarks
We selected two primary benchmarks for evaluation:
- Google’s FRAMES: This is the primary evaluation benchmark we tested against. It tests:
- Multi-hop reasoning: Requires retrieval from multiple sources and reasoning over them.
- Temporal reasoning: Requires reasoning about time.
- Tabular reasoning: Requires reasoning on data in tables.
These align well with our retrieval and reasoning goals for Khoj. The benchmark was released in September 2024 by Google. It is a public, reasonably challenging dataset for modern AI agents4.
- OpenAI’s SimpleQA: This is a recently released evaluation benchmark.
- It evaluates the ability of large language models to give correct and truthful answers.
- It was created as a challenging Q&A benchmark for modern LLMs. Top models like o1-preview and the latest claude 3.5 sonnet only get ~40% answers correct.
These match our helpfulness goals for Khoj. This benchmark was released a few weeks ago by OpenAI. It is open-source and challenging for current state-of-the-art LLMs.
Evaluated Modes
Khoj can be interacted with in a few different modes. The 3 main ones from the lens of the evaluations are:
- General: This is like a closed book exam. No retrieval is allowed. The agent can’t access external information, only the LLMs existing general knowledge.
- Default: This is like an open book exam. Single shot retrieval is allowed. The agent can search for information online, run calculations in a code sandbox.
- Research: This is like a take home exam. Iterative retrieval is permitted. The agent can do deeper research for a bit longer with the same web search and code tools.
You can chat with Khoj in any of the 3 modes using a slash command like /research. Default mode doesn’t require slash command. Research mode was released at the start of November and is still in beta.
Evaluation Harness
We developed an evaluation script to quiz Khoj on different benchmarks5. It allows you to:
- Configure sample size, randomization, target benchmark.
- Test multiple modes: General vs. Default vs. Research.
- Track running accuracy and costs during the evaluation run.
The eval is automatically run on every release using a Github workflow. The workflow:
- Boots up a local Khoj instance with gemini-1.5-flash-002.
- Gives it the ability to search the web and run code.
- Quizzes Khoj on 200 random questions from the FRAMES benchmark.
- Grades the responses using gemini-1.5-pro-002 as the LLM judge.
- Publishes the scores and a downloadable report for verification.
Using a public evaluation workflow provides transparency at multiple levels. It creates an audit trail to inspect the setup, reasoning traces and detailed results of Khoj’s performance across time and code changes. You can see the raw logs from a recent eval workflow run here.
Results
These runs evaluate Khoj with gemini-1.5-flash-002 on a 200-question random subset of the target benchmark6. This results in error margins of ~6% at reasonable costs ($5 across the 3 modes and 2 benchmarks).
| Benchmark | General | Default | Research | Baseline |
|---|---|---|---|---|
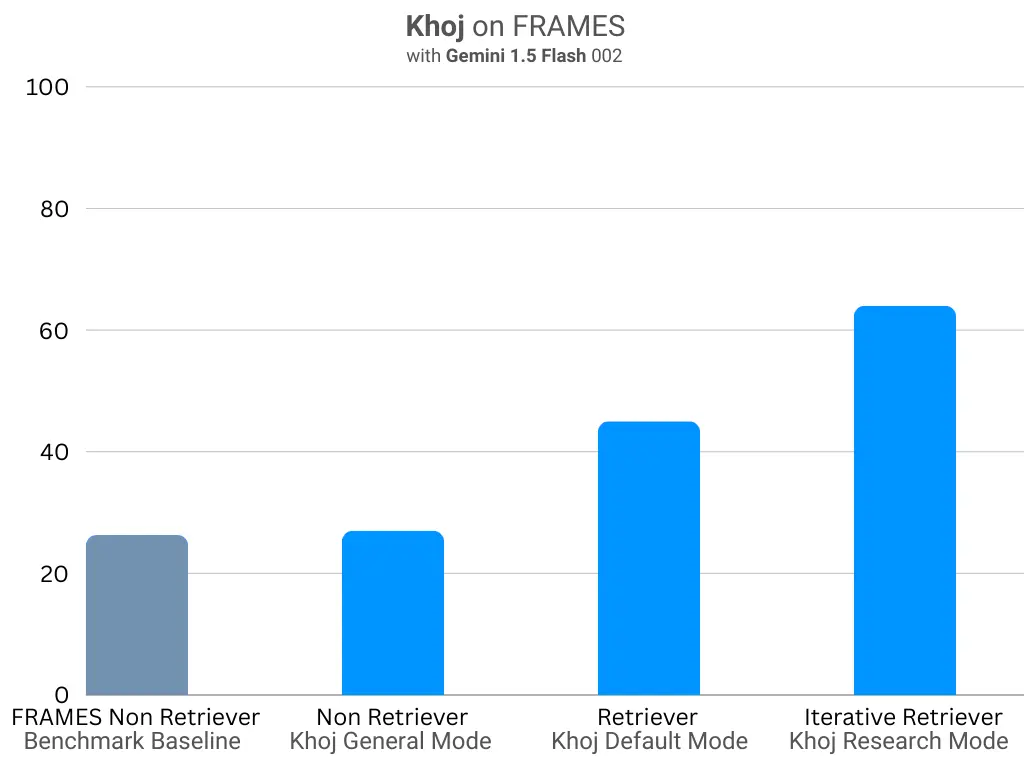
| FRAMES | 27.1 | 42.0 | 63.5 | 26.3 (flash-1.5-001) |
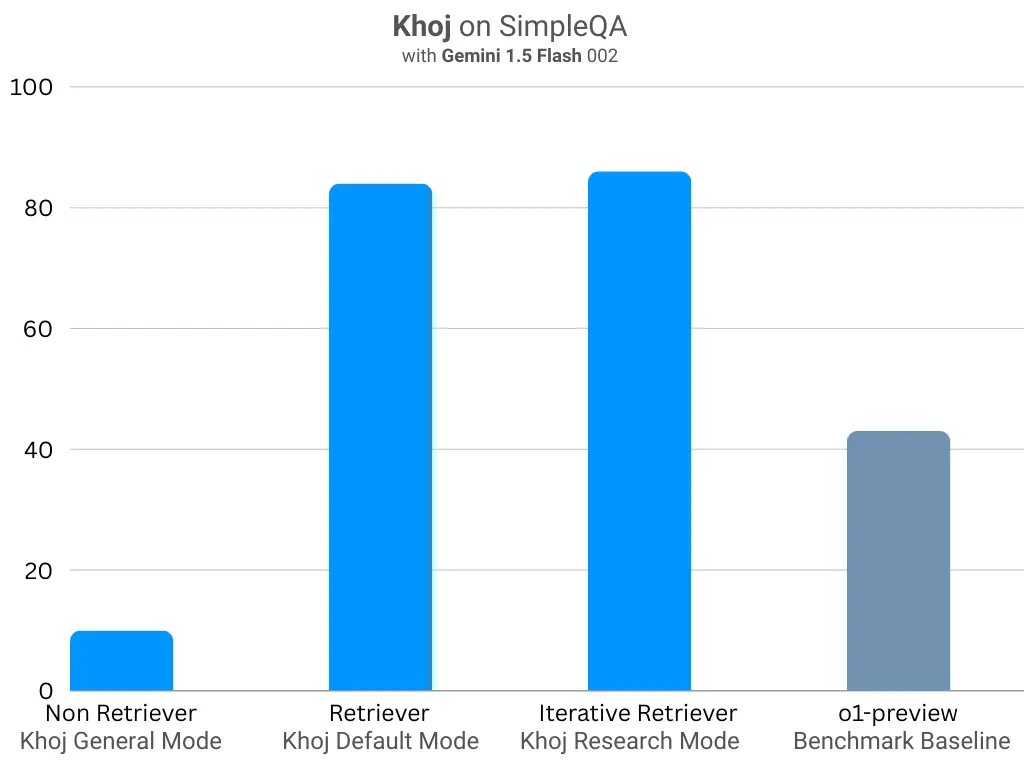
| SimpleQA | 10.0 | 84.0 | 86.0 | 43.5 (o1 preview) |
The graphs below visualize the improvements across the 3 modes on the evaluated benchmarks:
Key Findings
Khoj upgrades small hosted LLMs into AI agents that perform at or beyond the capabilities of state-of-the-art LLMs across both these modern benchmarks.
Improvements on the FRAMES Benchmark
- General to Default mode: 54.8% improvement from 27.1% to 42.0%.
- Default to Research mode: 51.2% additional improvement from 42.0% to 63.5%.
- Khoj more than doubled (141.4%) the accuracy of gemini-1.5-flash from the baseline of 26.3% to 63.5%. This seems close to saturating the models reasoning capabilities on this benchmark.
- Khoj research mode upgrades gemini-1.5-flash (63.5%) to achieve gemini-1.5-pro performance (66%) with the multi-step retrieval from the FRAMES paper.
- For reference when shown all relevant documents gemini-1.5-flash achieves a 66.5% score. This is the ceiling of the model’s reasoning capabilities given perfect retrieval.
Improvements on the SimpleQA Benchmark
- General to Default mode: 740.0% improvement from 10.0% to 84.0%.
- Default to Research mode: 2.4% additional improvement from 84.0% to 86.0%.
- The massive jump from General to Default mode seems to saturate the eval. The research mode accuracy is reported just for completeness.
- Khoj upgrades small LLMs to achieve 2x the accuracy of modern state-of-the-art LLMs and close to human performance on the SimpleQA benchmark.
- For reference the strongest model, o1-preview, scores a 43.5% and humans got a 94.4%7.
Impact of Code Interpreter Tool
Khoj can run code. This ability results in notable accuracy improvements. Here are the results of its impact on the FRAMES benchmark when run in Default mode:
- Accuracy without code tool: 35.68%.
- Accuracy with code tool: 42.00%.
- Net relative improvement: ~18% from 35.68% to 42.00%.
Future Work
- Add ability to efficiently test retrieval across internal and external knowledge. Our current eval only measures retrieval from the internet, not from your documents.
- Test ability to retrieve, reason over and provide helpful multi-modal answers. Our current eval only tests uni-modal, text based information retrieval and reasoning.
- Test reasoning over multi-turn interactions with a user. Our current eval only tests single turn interactions. This does not match Khoj’s real-world interaction patterns.
- Test confidence calibration similar to what is done in the official SimpleQA evaluations.
These enhancements should improve our test coverage and understanding of performance on a more complete set of Khoj’s capabilities and user interactions.
Conclusion
We built a transparent, automated evaluation harness. Our evaluations show Khoj significantly enhances base model performance across multiple modern benchmarks.
Through systematic testing and continuous monitoring, we can now quantitatively track and improve Khoj’s helpfulness across different modes, models and time.
You can fork our eval script & workflow to adapt it as an automated eval harness for your agents.
Footnotes
Footnotes
-
For the scope of this post, we define helpfulness as the ability to accurately and truthfully answer a query. ↩
-
The uncertainty motivated us to build this automated evaluation harness to track and catch any drops in quality across time. ↩
-
We expect dangerous behaviors and capabilities to appear in AI agents before LLMs. Building systems to detect and isolate these at the AI agent layer is important. That topic needs a separate post. You can read this post until then. ↩
-
While FRAMES has good quality questions, it has a somewhat limited score range (26% to 66% for flash) for testing the models retrieval capabilities as an agent. ↩
-
We verified that gemini-1.5-flash-002 in general mode on our eval get similar baseline score as gemini-1.5-flash-001 on the FRAMES paper of 26.3%. ↩
-
Similar quality improvements were seen in our internal evaluations of 4o-mini on a 100 random question subset of both the benchmarks. ↩
-
The performance jump on SimpleQA suggests either remarkable effectiveness of Khoj’s approach or potential brittleness in the benchmark itself. Or maybe our eval is broken? ↩