Timely: A Date-Aware Embedding Model

Timely: An Embedding Model For Temporal Reasoning
At Khoj, we develop open-source personal AI to simplify how people engage with machines. The RAG component in modern AI systems commonly uses an embedding model to retrieve relevant documents for a user query. This retrieved-context enables accurate and personalized responses.
However, most of these models struggle with temporal reasoning. For instance, if asked “Where was I last summer?”, the model would struggle to understand the framing of that question. It requires us to understand the relativity of time (that 2010 is before 2011), and when summer might be (between May - September).
When we express dates, we often use shorthands like ‘back in June’, ‘on summer break’, and ‘06/15’; all syntaxes that models don’t presently handle well. As such, your embedding model may not find documents with dates within that specific period. This limitation is significant, given the importance of time and date in language and daily life.
To address this problem, we propose Timely, a comprehensive pipeline for date-aware dataset generation, model fine-tuning, and benchmarking. Specifically, our goal is to create models that can:
- Identify natural language dates in queries and documents better
- Can handle relative and soft data filters more naturally (e.g. discerning that June is closer than November when talking about Spring).
Overview of Embedding Models
Embedding models work by converting queries and documents into high-dimensional vectors. The similarity between these vectors is then calculated to determine how conceptually related they are. Vectors that are closer together in this high-dimensional space are considered more related, while those further apart are less related or unrelated.
The similarity between vectors can be calculated using the cosine similarity formula:
# Function to calculate the cosine similarity between two vectors A and B
def cosine_similarity(A, B):
# Calculate the dot product of vectors A and B
dot_product = sum(a * b for a, b in zip(A, B))
# Calculate the magnitude of vector A
magnitude_A = sum(a**2 for a in A) ** 0.5
# Calculate the magnitude of vector B
magnitude_B = sum(b**2 for b in B) ** 0.5
# Calculate the cosine similarity
similarity = dot_product / (magnitude_A * magnitude_B)
return similarityDataset Preparation
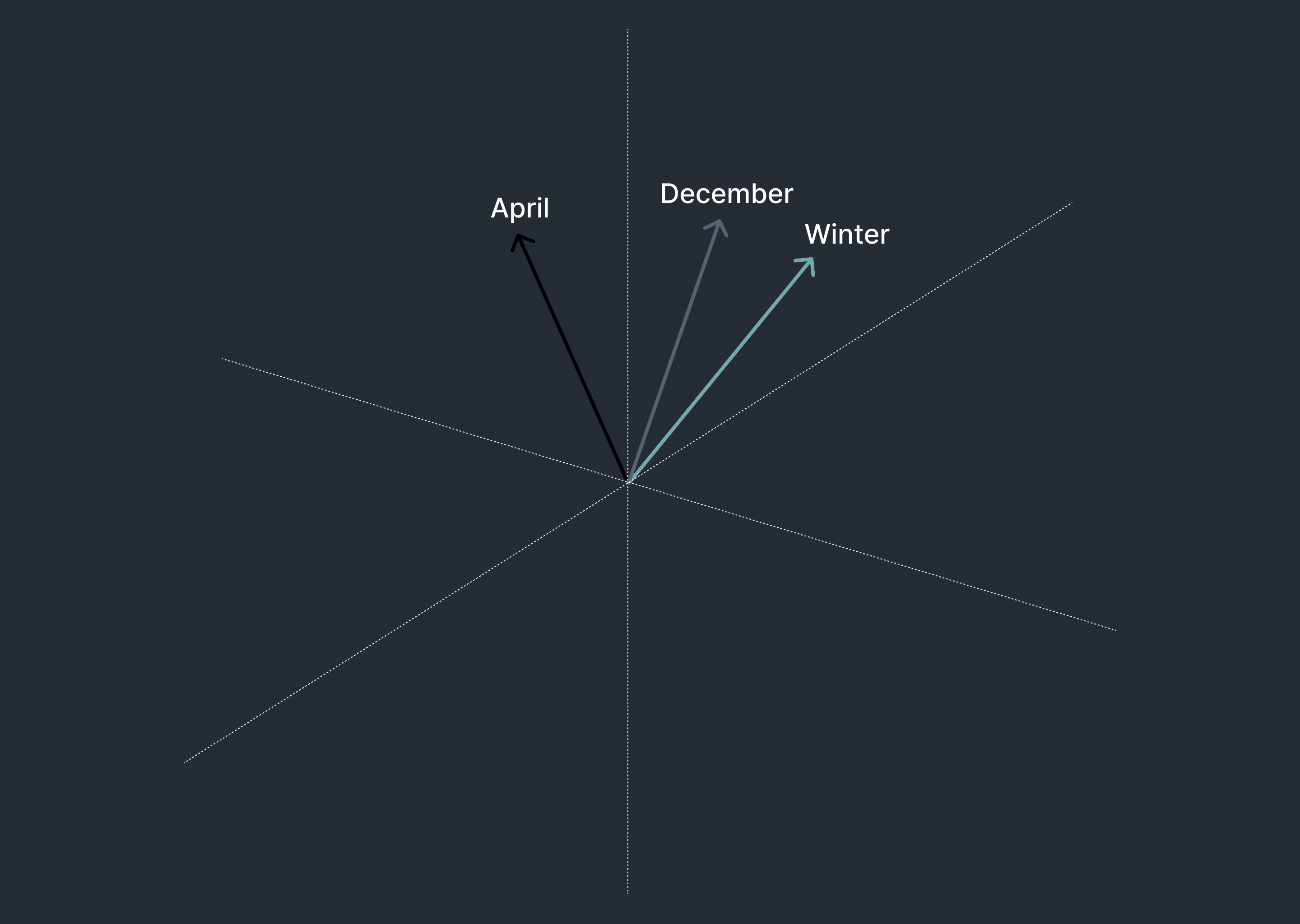
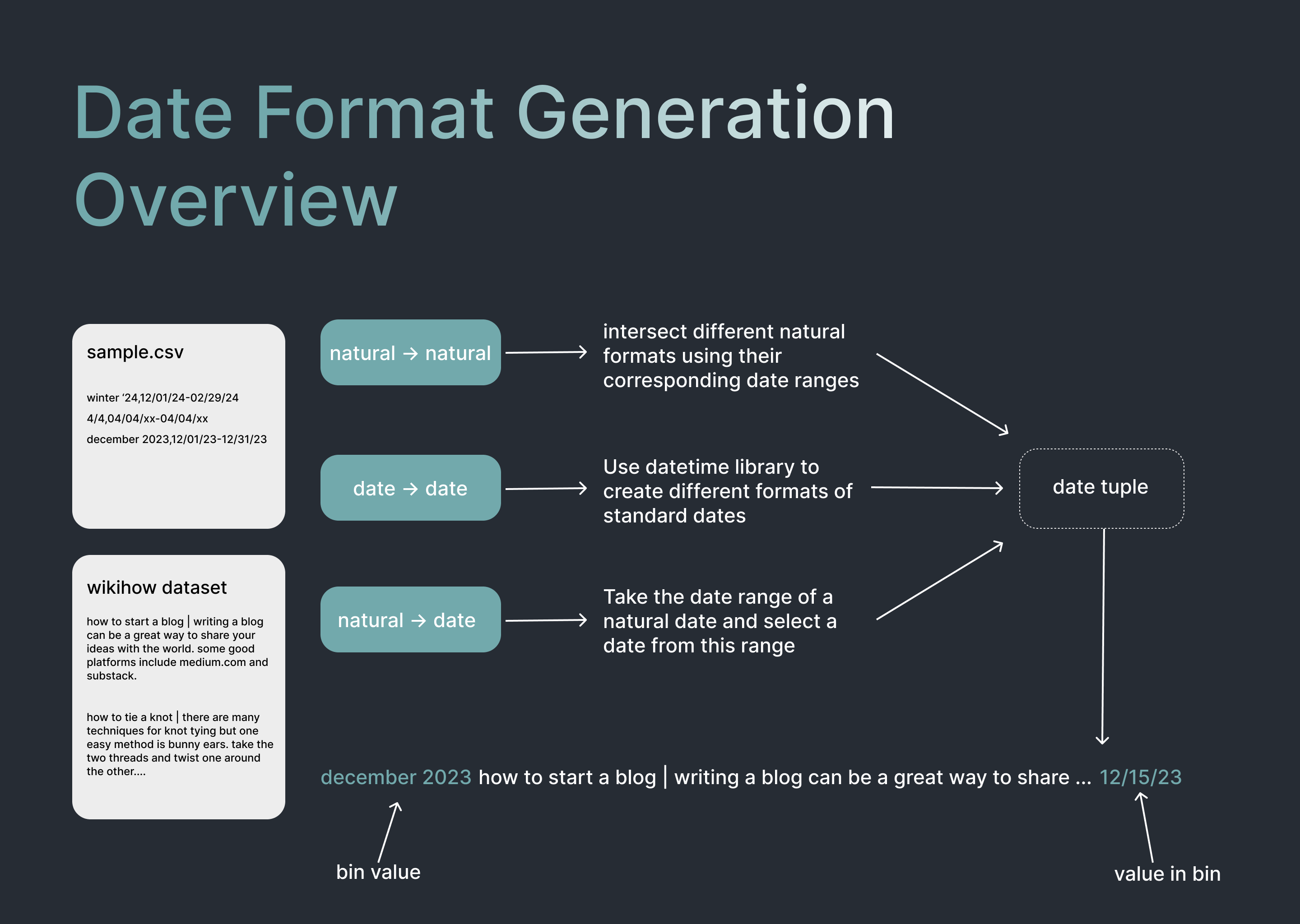
To improve temporal reasoning, we fine-tuned a base embedding model to bring vectors of similar temporal descriptions closer together. This process required generating diverse, high-quality data matching descriptions of dates in various formats.
We started with the wikihow dataset and augmented query-document pairs with temporal descriptors. For example, a query might be appended with “today:2024-04-01 last spring” and the corresponding document with “spring 2023” or “03/15/2023”. We generated various date formats programmatically and included plain WikiHow query-document pairs to prevent overfitting.
Evaluation
We created benchmarks using a strategy similar to our dataset generation, with new query-document pairs and various date formats based on unused sentences from various datasets. For each query and document, a correct date document and incorrect document were prepared resulting in a triplet like format. For each triplet the model is tasked with selecting the correct document and the accuracy is measured. The datasets used were WikiHow, Google Answer Question, and Wikipedia which correspond with Timely WikiHow (Benchmark 1), Timely Google (Benchmark 2), and Timely Wikipedia. In Experiment 2, we also included MTEB benchmarking on the DBPedia and QuoraRetrieval tasks which will be explained further in a later section.
Phase 1: Improving Date Awareness
Training
We initially used a T4 GPU for training runs and later upgraded to an NVIDIA A100 as our dataset grew beyond 100,000 entries. We primarily used the nomic-embed-v1 embedding model but switched to arctic-embed models for our final release to offer small, medium, and large model variants.
Training parameters remained largely consistent across iterations, aligning with the Nomic technical report:
nomic-embed-v1 fine-tuning:
- Batch size: 8 or 64 (v5 and upwards)
- Epochs: 1
- Learning rate: 2.0e-5
- Loss function: Multiple negatives ranking loss
- Binary floating point 16
- Warmup ratio: 0.1
- Weight decay: 0.01
- Warmup steps: 400
arctic-embed fine-tuning:
- Same as above, but with a learning rate of 1.0e-5
Our iterative process focused on improving:
- Dataset diversity
- Generalization
- Dataset size
Version History
We went through multiple iterations, each improving various aspects of the model. Here’s a summary of key versions:
- v0.1 - v0.5: Gradually increased dataset size and diversity, showing improvements in date matching and natural format recognition.
- v0.6 - v0.8: Scaled up to millions of data points, addressed MTEB degradation, and improved performance on diverse benchmarks.
- v0.9 (version 1): Final release with 1.3-2.1M data points, increased diversity, and improved support for relative date formats.
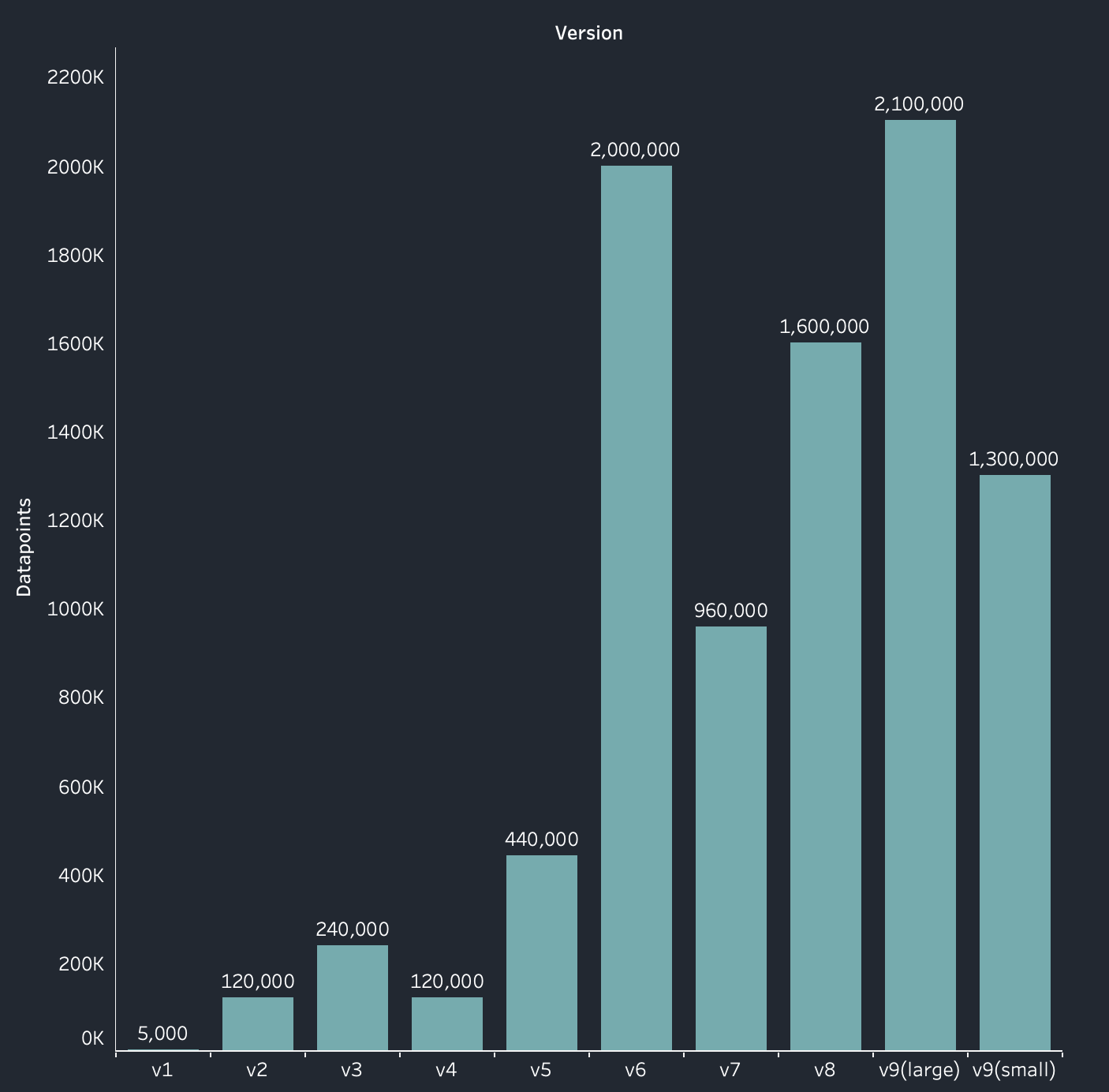
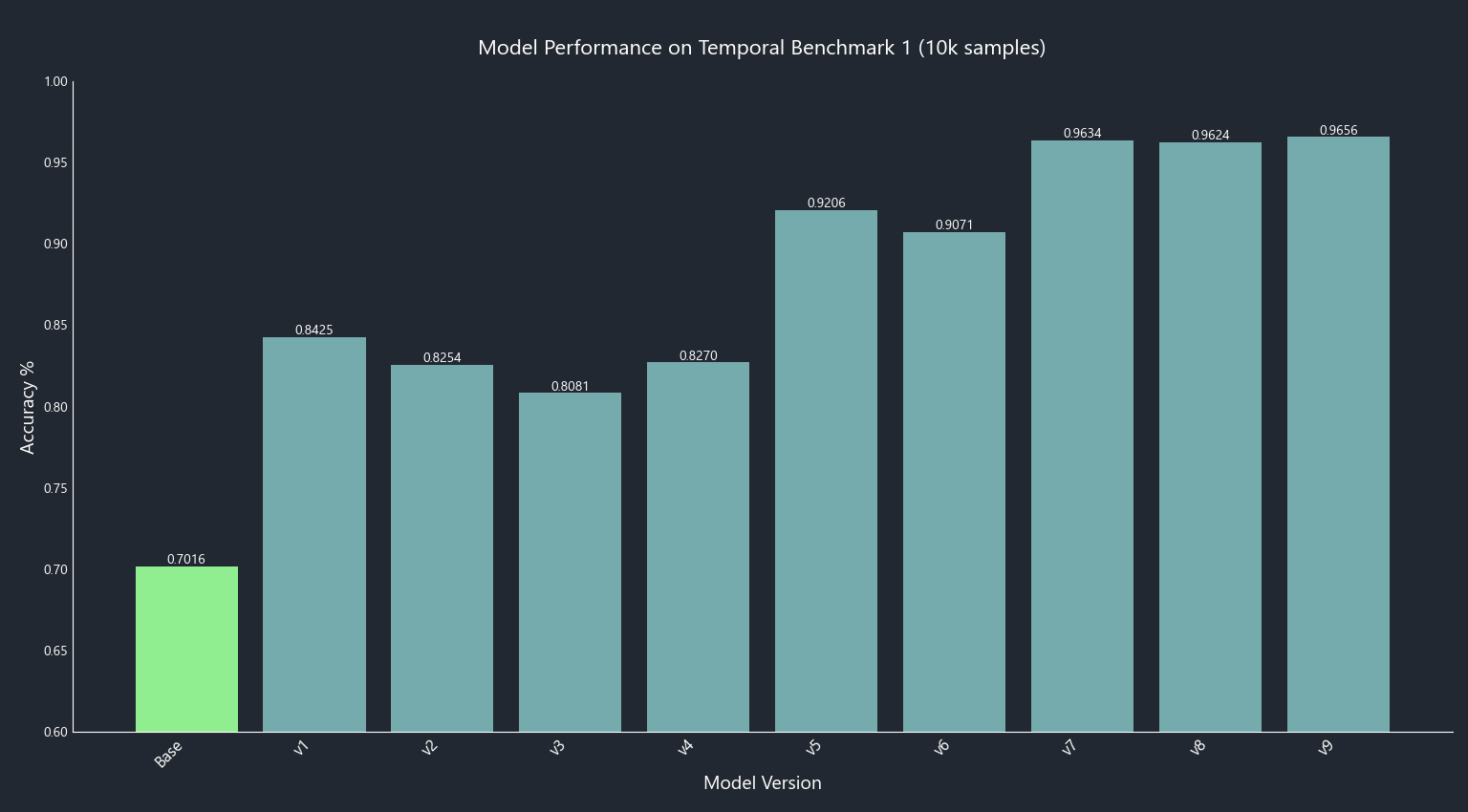
This graph shows that even a small amount of fine-tuning significantly improves performance, with dataset diversity correlating with benchmark performance improvements.
The final benchmark results for our three tiers of Timely models (small, medium, and large) compared to their base models show that all fine-tuned models achieve close to 90% accuracy, with the small model showing the largest performance improvement.
At the end of this process, we were left with some unresolved issues. In terms of MTEB scoring, our models had a substantial loss in general retrieval abilities compared to the reported scores from the Arctic and Nomic base models. This led to our second phase of experimentation.
Findings and Conclusion
Key insights from our process include:
- Dataset quality is crucial for achieving good performance
- Scaling dataset size without increasing diversity can lead to overfitting and performance degradation
- Consulting technical reports for base embedding models can reveal optimal training parameters
Phase 2: Improving General Reasoning Ability
As mentioned before our final timely models from experiment 1 suffered from large MTEB loss. While it’s hard to run the entire MTEB benchmark due to resource and time constraints we identified two retrieval benchmarks that could be used to measure degradation. These were QuoraRetrieval which is a sentence-to-sentence benchmark and DBPedia which is a sentence-to-paragraph benchmark based on structured Wikipedia data. On these two metrics, our initial timely models took hits of around 5% and 11% respectively, indicating that our models wouldn’t scale well to general reasoning tasks. For this reason, we decided to do another round of modifications to improve these benchmark scores while retaining as much performance on the timely benchmarks as possible. Below are some factors that we experimented with.
Factors that helped
Dataset Diversity
Even with a small dataset of just 5000 pairs we were measuring large drops in MTEB performance. We inferred that the quality of our data was inadequate. To address this, we looked for other base datasets to use in our date awareness augmentation process. Rather than just using WikiHow data, the dataset now included a combination of Wikipedia, Google Answer Question, and HotpotQA. We augmented each of these datasets with the methodology described in dataset preparation. We filtered out passages with existing date information and passages with excessive length as initial experiments revealed that these data points reduced performance. This improved our DBPedia benchmark score by about 4%.
Hard Negatives
Looking at the literature from Snowflake’s Arctic model, we found that mining hard negatives leads to better learning outcomes for the model. For each pair of query documents, 3 variants of the same query documents were included with different temporal formats so that the model focused on the date information.
Curriculum Learning
Curriculum learning is a technique where the examples start out easy and become progressively difficult. For our purposes this was accomplished by putting small examples with direct date formats first and larger examples with relative date formats towards the end. For example:
- are bugs attracted to citronella November 10?|Citronella is naturally occurring oil that repels insects. … “Citronella oil is repellent to mosquitoes to a degree, but the amount being put out by a candle isn’t going to be very effective,” Eric Hoffer, president of Hoffer Pest, told TODAY Home. 11/10
- today:2003-11-15 29 days ago how can i change my middle name on facebook?|2003-10-17 Your name will be the first thing listed under your General Account Settings. Click the “Edit” button on the right of the screen and you’ll see the options to change your name. At this point, you can change your first name, your last name, or a middle name, as well as add other names.
- today:2043-06-22 last spring Canal de Calais|2042 may 31 The Canal de Calais connects the Aa River near Ruminghem to the inner basins of the Port of Calais. Many boats enter the French canal system through the port of Calais and this canal. It is 30 km long and has 3 locks. History Work started on the canal in the late 17th century, but it was not opened until 1758. The canal was enlarged for Class II ‘Campinois’ and ‘Canal du Nord’ craft in the 1980s over two thirds of its length. The upgrading remains incomplete. See also List of canals in France References External links Canal de Calais Maps and details of places, ports and moorings on the canal, including the port of Calais as an entry port into the French Waterways. Navigation details for 80 French rivers and canals (French waterways website section) Canals in France
Freezing Layers
While this technique doesn’t seem to be talked about too frequently in the embedding model literature, freezing early layers can be used to prevent catastrophic loss in the model by allowing the finetune process to only adjust layers near the end. We found that this technique led to improvements in MTEB metrics, as it helped avoid undermining the model’s general knowledge through the training process.
Hyperparameter Tuning
Going back to the basics of Machine Learning, we conducted Hyperparameter tuning experiments on each model to identify the best training parameters that balance out Timely and MTEB benchmarks. Each arctic embed model has its own architecture so this proved vital to ensure optimal training behavior at each level. Specifically, we adjusted batch size, number of frozen layers, and learning rate.
Factors that weren’t so helpful
Matryoshka Loss
While the literature suggests that Matryoshka Loss can help ensure generalization while finetuning embedding model and can also allow for smaller embedding vectors, from our experiments we found that it led to degradation in MTEB and Timely performance
Triplets
While many models like Arctic Embed and Nomic Embed employ triplets instead of query-document pairs during training, we found that it posed no additional improvements in performance on Timely and MTEB.
Increased Dataset Size
While the common advice is to improve dataset diversity while scaling the dataset size, we found that larger Timely datasets led to further MTEB degradation. The cause for this is still not fully identified but the theory is that our dataset diversity is still lacking as much of the Arctic Embed finetuning dataset consists of proprietary web data
Model Training Details
timely large
- batch size: 32
- number of frozen layers: 3 of 23
- learning rate: 1e-6
- dataset size: ~50,000
timely medium
- batch size: 128
- number of frozen layers: 8 of 11
- learning rate: 1.5e-5
- dataset size: ~50,000
timely small
- batch size: 128
- number of frozen layers: 8 of 11
- learning rate: 1.5e-5
- dataset size: ~50,000
Results
Description of Tasks:
- QuoraRetrieval: An MTEB sentence-to-sentence task that tests a model’s retrieval abilities using data from Quora
- DBPedia: An MTEB sentence-to-paragraph task that tests a model’s retrieval abilities using structured data from Wikipedia
- Timely Wikipedia: A custom Timely task designed to test a model’s ability to select between identical documents with different dates given a query using Wikipedia data
- Timely Google: A custom Timely task designed to test a model’s ability to select between identical documents with different dates given a query using Google Answer Question data
- Timely WikiHow: A custom Timely task designed to test a model’s ability to select between identical documents with different dates given a query using WikiHow data
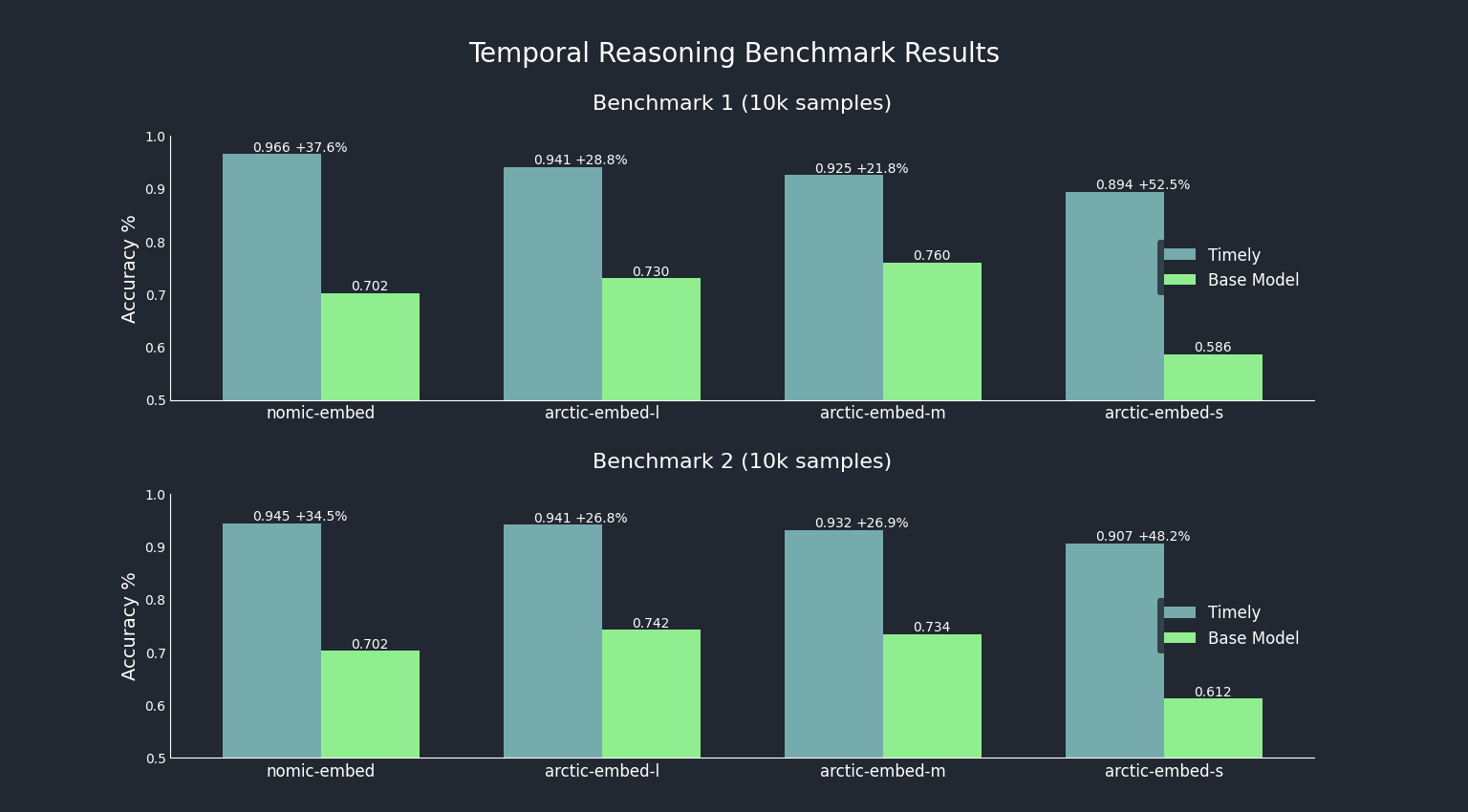
| QuoraRetrieval | DBPedia | Timely Wikipedia | Timely Google | Timely WikiHow | |
|---|---|---|---|---|---|
| Timely Small (Experiment 1) | 0.82189 | 0.29394 | 0.9164 | 0.9039 | 0.8906 |
| Timely Small | 0.86062 | 0.36572 | 0.8651 | 0.8650 | 0.8578 |
| Timely Medium | 0.86439 | 0.40889 | 0.9031 | 0.8891 | 0.8894 |
| Timely Large | 0.87331 | 0.40851 | 0.9046 | 0.9026 | 0.8928 |
| Arctic Small | 0.8747 | 0.4159 | 0.6529 | 0.612 | 0.586 |
| Arctic Medium | 0.8742 | 0.4473 | 0.822 | 0.734 | 0.760 |
| Arctic Large | 0.8741 | 0.4597 | 0.7509 | 0.742 | 0.730 |
From these results, we see that our original timely model, while formidable in the Timely benchmarks, has a large amount of general reasoning degradation as seen in the QuoraRetrieval and DBPedia scores. Our new models achieve improvements to Timely performance while reducing the degradation in MTEB scores.
Future Work
Our future focus includes:
- Incorporate smaller natural time formats (e.g. 8 pm, morning, sunrise, sunset).
- Improve dataset quality using synthetic LLM-generated query-document pairings.
- Further Improvements to general reasoning ability.
Reproduce
Pretrained Models, Benchmarks, Datasets
To download our fine-tuned Timely models visit our HuggingFace page here: huggingface
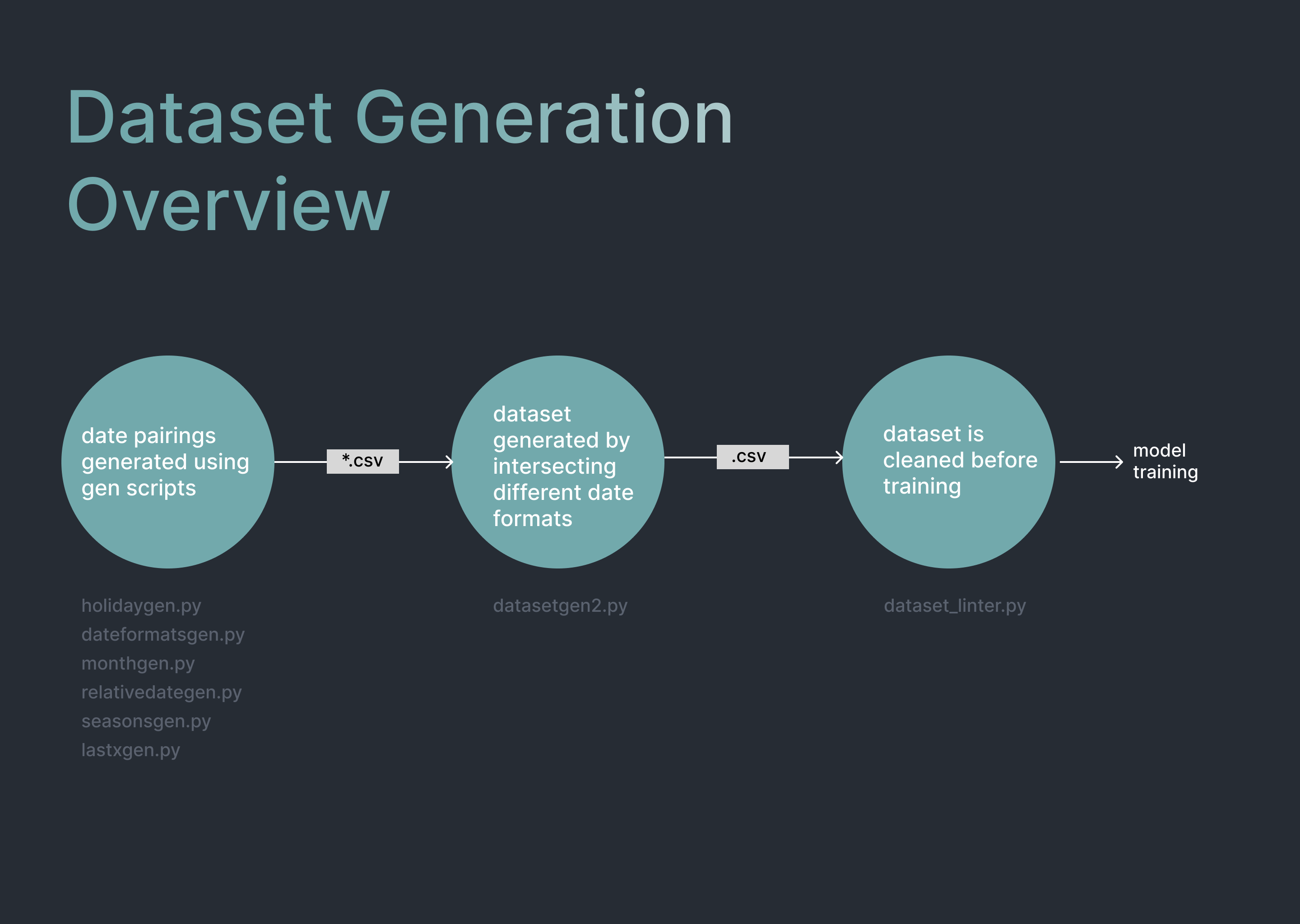
Dataset Generation
To replicate dataset generation use the following steps:
- Run all files ending in “gen.py” (excluding gradientgen, benchgen, and datasetgen) to generate date tuple csv files
- Run
py date_to_date.py - Run
py natural_to_date.py - Run
py natural_tuples.pyrerunninglastxgen.pyandrelativedategen.pywith a smaller sample size for improved speed. - Run
py datasetgen2.py. This will create a csv file in datasets titleddatasets/wiki_date_aware_diverse_v4.csv. Change as necessary - Run the output file through
dataset_linter.py - The output text file can be used in training.
- Alternatively, at step 5
py datasetCombiner.pyfollowed bypy datasetgen3.pywill create a more diverse dataset used in Experiment 2. Modify the output file of datasetCombiner to match the input file of datasetgen3.
Model Training
- Start a Google Colab Instance with an A100 for optimal speed
- Upload the desired
.txtdataset - Open the
training.ipynbnotebook. - Adjust batch size and other parameters as necessary
- **IMPORTANT: ** After pip installation, use the command at the end of the notebook to refresh pip installations.
- Run all other lines starting at the python imports
Benchmarking
- Load the desired benchmark and trained model
- Run all code blocks in
testing.ipynb
Questions
For any questions or suggestions feel free to contact [email protected]